pandas Groupby: split-?-combine#
When choosing what groupby operations to run, pandas offers many options. Namely, you can choose to use one of these three:
aggoraggregatetransformapply
This blog post takes the guesswork out of whether you should agg, transform, or apply your groupby operations on pandas objects.
Reducing vs Non-Reducing Functions#
To better grasp the differences between pandas groupby, agg, transform and apply, we first need to differentiate reducing functions from non-reducing functions.
from IPython.display import Markdown, display
from pandas import Series, DataFrame, Index
from numpy.random import default_rng
x = Series([1, 2, 3, 4, 5])
x
0 1
1 2
2 3
3 4
4 5
dtype: int64
Reducing functions N → 1
Reduces the size of the input array to a scalar output.
sum([1, 2, 3])→6is an example of a reduction. The input[1, 2, 3]is being reduced to a single value6by some operationsum
These are commonly aggregation functions (e.g. sum, mean, median)
Can also be item selections (e.g.,
first,nth,last)
x.sum()
15
Non-Reducing functions N → N
Maintains the original size of the input array while transforming the original values
log10([10, 100, 1000])→[1, 2, 3]is an example of a non reducing transformation because the output has just as many values as the input
Functions operate “element-wise” (on each element) in an array and return a new value
e.g.,
log,log10,pow,cumsum,add,subtract
x.pow(2)
0 1
1 4
2 9
3 16
4 25
dtype: int64
Groupby Operations#
In pandas, groupby operations work on a “split → apply → combine” basis. This means that the data is first split into groups, some function is then applied to each group, and then those resultant pieces are recombined into the final DataFrame
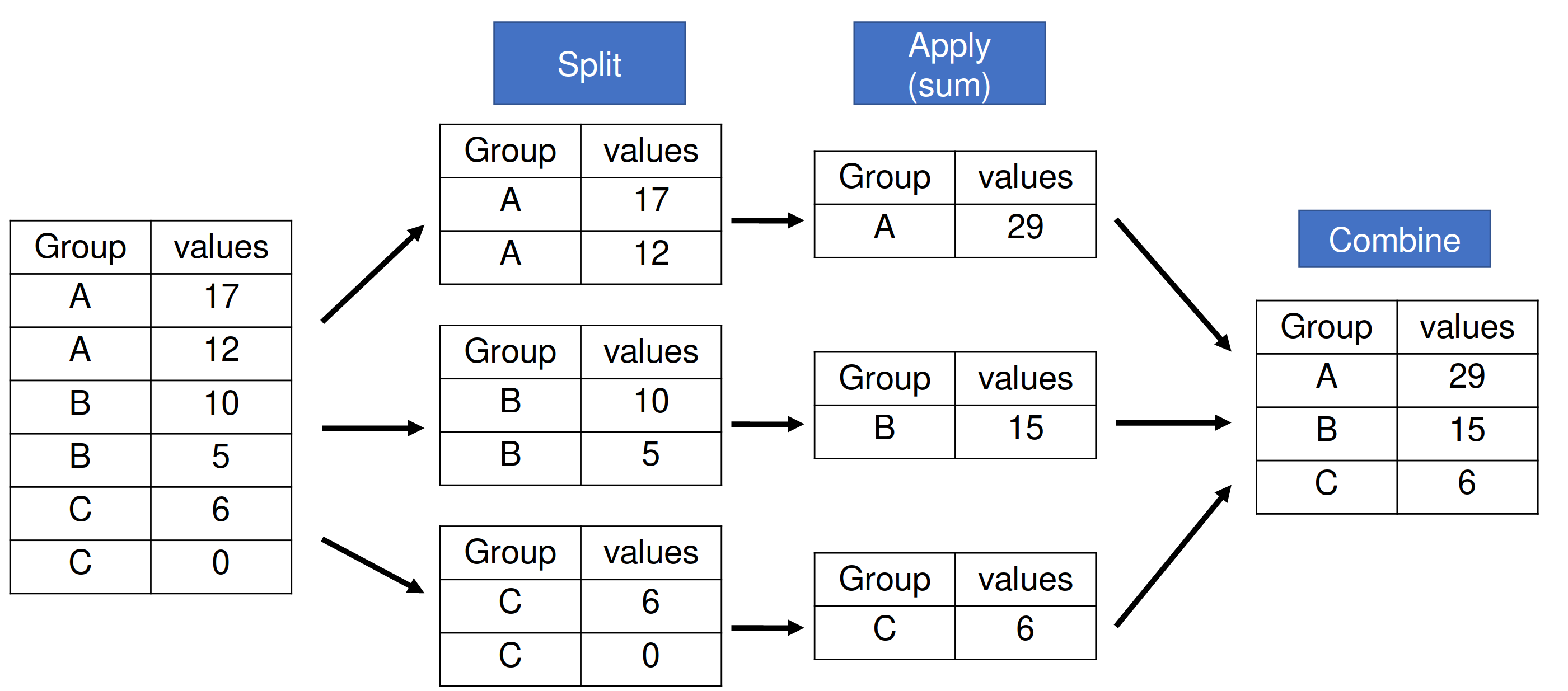
But, if it’s as simple as the operation depicted above, then why does pandas have 3 options when performing a .groupby operation: .agg, .transform, and .apply?
The reason is in the speed of the operation. By laying out certain assumptions of the outputted shape of the combination step (e.g., N → N or N → 1), pandas can take some shortcuts to ensure that our operations are applied as quickly as possible. As you may have guessed, the resultant shape is very closely tied to whether the function we want to apply is a reducing or a non-reducing function!
Let’s make some data to demonstrate:
rng = default_rng(0)
df = DataFrame(
index=(idx := Index(["a", "b", "c"], name='Group').repeat(3)),
data={
'values1': [34, 25, 20, 10, 12, 1, 3, 0, 7],
'values2': [39, 41, 15, 20, 25, 31, 10, 9, 4],
}
)
df
| values1 | values2 | |
|---|---|---|
| Group | ||
| a | 34 | 39 |
| a | 25 | 41 |
| a | 20 | 15 |
| b | 10 | 20 |
| b | 12 | 25 |
| b | 1 | 31 |
| c | 3 | 10 |
| c | 0 | 9 |
| c | 7 | 4 |
DataFrame.groupby(…).agg#
.aggonly works with functions that reduce.For user defined functions,
.aggoperates on each column independently this means that you cannot operate across columns with.agg
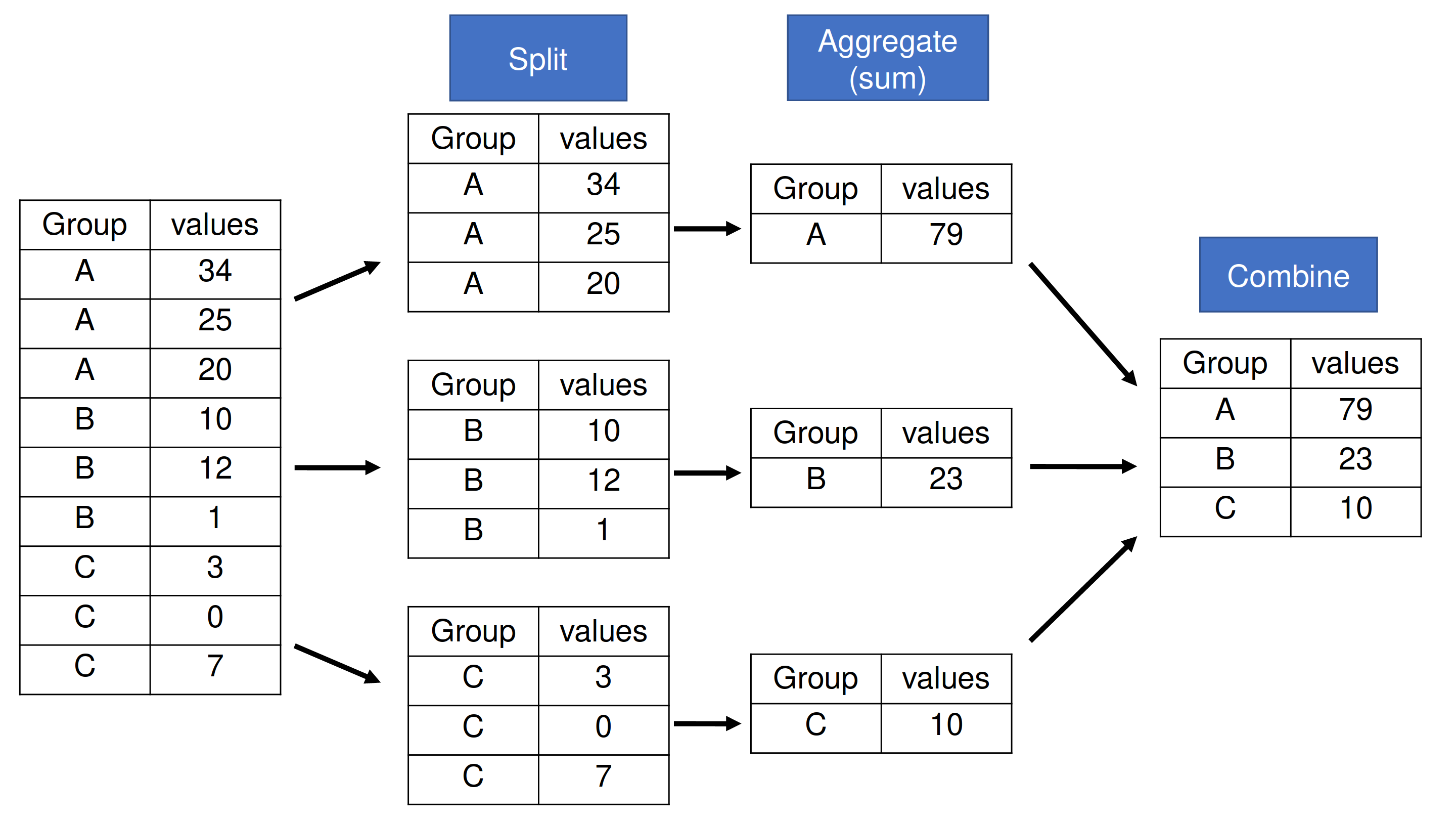
When working with multiple columns—as our data set contains—pandas will apply the function to each column within each group separately. This means it cannot use .groupby(…).agg() for values from multiple columns in the function passed to .agg.
There are many ways to pass functions into .agg. One is to pass multiple reduction functions as a list. Note that I receive an output for each of my original columns. To read on how else you can pass in functions to .agg, check out the pandas.core.groupby.DataFrameGroupBy.aggregate documentation
df.groupby('Group').agg([sum, 'mean', lambda s: False])
| values1 | values2 | |||||
|---|---|---|---|---|---|---|
| sum | mean | <lambda_0> | sum | mean | <lambda_0> | |
| Group | ||||||
| a | 79 | 26.333333 | False | 95 | 31.666667 | False |
| b | 23 | 7.666667 | False | 76 | 25.333333 | False |
| c | 10 | 3.333333 | False | 23 | 7.666667 | False |
If we pass a user defined function that does not reduce, we see this error:
df.groupby('Group')['values1'].agg(lambda s: s * 2)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [6], in <cell line: 1>()
----> 1 df.groupby('Group')['values1'].agg(lambda s: s * 2)
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/core/groupby/generic.py:297, in SeriesGroupBy.aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
294 return self._python_agg_general(func, *args, **kwargs)
296 try:
--> 297 return self._python_agg_general(func, *args, **kwargs)
298 except KeyError:
299 # TODO: KeyError is raised in _python_agg_general,
300 # see test_groupby.test_basic
301 result = self._aggregate_named(func, *args, **kwargs)
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/core/groupby/groupby.py:1682, in GroupBy._python_agg_general(self, func, raise_on_typeerror, *args, **kwargs)
1678 name = obj.name
1680 try:
1681 # if this function is invalid for this dtype, we will ignore it.
-> 1682 result = self.grouper.agg_series(obj, f)
1683 except TypeError:
1684 if raise_on_typeerror:
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/core/groupby/ops.py:1081, in BaseGrouper.agg_series(self, obj, func, preserve_dtype)
1078 preserve_dtype = True
1080 else:
-> 1081 result = self._aggregate_series_pure_python(obj, func)
1083 npvalues = lib.maybe_convert_objects(result, try_float=False)
1084 if preserve_dtype:
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/core/groupby/ops.py:1109, in BaseGrouper._aggregate_series_pure_python(self, obj, func)
1105 res = libreduction.extract_result(res)
1107 if not initialized:
1108 # We only do this validation on the first iteration
-> 1109 libreduction.check_result_array(res, group.dtype)
1110 initialized = True
1112 counts[i] = group.shape[0]
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/_libs/reduction.pyx:13, in pandas._libs.reduction.check_result_array()
File ~/.pyenv/versions/dutc-site/lib/python3.10/site-packages/pandas/_libs/reduction.pyx:21, in pandas._libs.reduction.check_result_array()
ValueError: Must produce aggregated value
DataFrame.groupby(…).transform#
.transform works with both non-reducing and reducing functions.
A groupby-transform operation ensures that the DataFrame does not change shape after the operation. The original Index remains intact and is used to index the resultant DataFrame.
Non-reducing function
![]()
df.groupby('Group').transform(lambda s: s.cumsum())
| values1 | values2 | |
|---|---|---|
| Group | ||
| a | 34 | 39 |
| a | 59 | 80 |
| a | 79 | 95 |
| b | 10 | 20 |
| b | 22 | 45 |
| b | 23 | 76 |
| c | 3 | 10 |
| c | 3 | 19 |
| c | 10 | 23 |
Reducing function
![]()
However, when a reducing function is used, the outputted value maps back to the shape of the original input to ensure an N → N grouped operation.
df.groupby('Group').transform(sum)
| values1 | values2 | |
|---|---|---|
| Group | ||
| a | 79 | 95 |
| a | 79 | 95 |
| a | 79 | 95 |
| b | 23 | 76 |
| b | 23 | 76 |
| b | 23 | 76 |
| c | 10 | 23 |
| c | 10 | 23 |
| c | 10 | 23 |
DataFrame.groupby(…).apply#
groupby(…).apply is the catch-all for pandas groupby operations. For user-defined functions, .apply works as follows:
N → M transformations (including N → 1 and N → N)
It works with entire sub-frames, instead of on a per column per group basis like
.aggand.transform
The actual mechanics of .apply are similar to the above, except that pandas struggles to make the same assumptions as it can with the .agg and .transform methods. This enables maximum flexibility for passing user defined functions to a groupby operation, at the cost of some performance speed.
Wrap Up#
That takes us to the end of this post! This should help orient you towards how you can better leverage .agg and .transform in your work, and only use .apply when you really need it.
In summary, you can think of groupby operations with the following table:
![]()
Talk to you all next time!