Faster strftime
Welcome back to this week's Cameron's Corner! Before we get started, I want to let you know about our upcoming public seminar series, "(Even More) Python Basics for Experts." Join James in this three-session series about (even more) Python basics that experts need to make their code more effective and efficient. He'll tackle what's real, how we can tell it's real, and how we can do less work.
On to the topic at hand. I wanted to tackle a fun pandas optimization problem, focusing on converting datetime objects to their date counterparts. For this problem, I did take it "head on," meaning I did not inquire why the end user wanted this output, just performed some benchmarking on their existing approaches and threw in a couple of my own.
To get started, let's make a dataset:
The Data
We have a pandas.Series with a 'datetime64[ns]' datatype. There was not a specification to the cardinality of the data, but the granularity was minute-wise. For the approaches below, I would suspect different results based on the granularity of the timeseries, as well as the presence of duplicates.
from pandas import Series, date_range, Categorical, merge
s = Series(date_range('2000-01-01', periods=1_000_000, freq='5min'))
display(
s.head(),
f'{s.shape[0] = :,} | {s.dt.floor("D").nunique() = }'
)0 2000-01-01 00:00:00
1 2000-01-01 00:05:00
2 2000-01-01 00:10:00
3 2000-01-01 00:15:00
4 2000-01-01 00:20:00
dtype: datetime64[ns]'s.shape[0] = 1,000,000 | s.dt.floor("D").nunique() = 3473'The goal is to end with something like this output, but, of course, on all 1M datapoints instead of just the first five. So, we effectively want to convert each of these dates from their minute granularity down to their corresponding day.
s.head().dt.strftime('%Y%m%d')0 20000101
1 20000101
2 20000101
3 20000101
4 20000101
dtype: objectThe Timer
To get started, I'm going to create a quick class to hold my timings so we can compare our micro-benchmarks later. The TimeManager class can be used as a context manager to track each approach via a passed string description.
from dataclasses import dataclass, field
from contextlib import contextmanager
from time import perf_counter
@dataclass
class Timer:
start: float = None
end: float = None
@property
def elapsed(self):
if self.start is None or self.end is None:
raise ValueError('Timer must have both end and start')
return self.end - self.start
@dataclass
class TimerManager:
registry: list = field(default_factory=list)
@contextmanager
def time(self, description):
timer = Timer(start=perf_counter())
yield timer
timer.end = perf_counter()
self.registry.append((description, timer))
print(f'{description:<30}{timer.end - timer.start:.6f}s')
timer, solutions = TimerManager(), []pandas
Let's first look at our first three approaches implemented in pure pandas.
Perhaps the most obvious is to simply use .dt.strftime with the desired output format.
We can deduplicate our pandas.Series, work across unique entities, then reindex back to our original positions.
Again deduplication, but instead of reindexing we recreate a new Categorical Series via pandas.Categorical.from_codes.
The comments in the code indicate who originated that specific snippet. Comments ending in CR indicate that I originated this snippet.
with timer.time('pandas|.strftime'): # ① end-user
solutions.append(
s.dt.strftime('%Y%m%d')
)
with timer.time('pandas|floor→dedupe→realign'): # ② CR
tmp = s.dt.floor('D').rename('date')
solutions.append(
tmp
.set_axis(tmp)
.drop_duplicates().dt.strftime('%Y%m%d')
.reindex(tmp)
.set_axis(s.index)
)
with timer.time('pandas|floor→factorize→strftime'): # ③ CR
codes, cats = s.dt.floor('D').factorize()
solutions.append(
Categorical.from_codes(codes, categories=cats.strftime('%Y%m%d'))
)pandas|.strftime 9.368280s
pandas|floor→dedupe→realign 0.080582s
pandas|floor→factorize→strftime0.056471sInteger Math
"numba makes everything fast, right?" I’m never a fan of blanket statements, but based on the function that numba.vectorize is being applied to, it does seem like it is a great candidate for some JIT compilation. The idea here is to end with an int64 that mimics the above string output. To push things into numba's advantage, I'll even skip on converting the end result to a string. For a comparison against the engineered numba approach I am going to use pandas to perform the same computation, just relying on multiplying each portion of the date (e.g., the .year by the appropriate number of decimal places I want it to end up in.
numba, perform math on the parts of a date
pandas, perform math on the parts of a date
import numba
from numba import vectorize, int64
@numba.vectorize([int64(int64)])
def nanos_to_yyyymmdd_numba(nanos: int) -> int:
"""
:WARNING: This is copy-pasted and pythonified from this C algorithm:
<https://howardhinnant.github.io/date_algorithms.html#civil_from_days>.
Tt has been only lightly checked over a range of ~20y for correct results.
"""
z = (nanos // 86400000000000) + 719468
era = (z if z >= 0 else z - 146096) // 146097
doe = z - era * 146097 # [0, 146096]
yoe = (doe - doe // 1460 + doe // 36524 - doe // 146096) // 365 # [0, 399]
y = yoe + era * 400
doy = doe - (365 * yoe + yoe // 4 - yoe // 100) # [0, 365]
mp = (5 * doy + 2) // 153 # [e, 11]
d = doy - (153 * mp + 2) // 5 + 1 #[1, 31]
m = mp + 3 if mp < 10 else mp-9
y = y + 1 if m <= 2 else y
return y * 10_000 + m * 100 + d
with timer.time('numba|parts math'): # ④ end-user
array_nanos = s.dt.tz_localize(None).to_numpy(dtype='int64', copy=False)
solutions.append(
nanos_to_yyyymmdd_numba(array_nanos)
)
with timer.time('pandas|parts math'): # ⑤ end-user
solutions.append(
(s.dt.year*10_000 + s.dt.month*100 + s.dt.day)
)numba|parts math 0.037193s
pandas|parts math 0.080999sPolars
Lastly, I thought, "Why not give Polars a shot?" It's supposed to blazingly fast, and I can confirm that claim with anecdotal evidence. So, let's see how it stacks up against the other tools/approaches. I'm going to recreate the two approaches I used in pandas for comparison.
Direct .strftime conversion
De-duplicate and self-join (pushes some work into a join instead of a date→string conversion)
from polars import from_pandas, col
pl_df = from_pandas(s.to_frame('ts')).lazy()
with timer.time('polars|strftime'): # ⑥ CR
solutions.append(
pl_df.select(col('ts').dt.strftime('%Y%m%d'))
.collect()
)
solutions[-1] = solutions[-1].to_pandas()['ts']
with timer.time('polars|date→dedupe→join'): # ⑦ CR
linkage = pl_df.with_columns(date=col('ts').dt.date())
solutions.append(
linkage
.unique('date')
.with_columns(date_str=col('date').dt.strftime('%Y%m%d'))
.join(linkage, on='date', how='inner')
.collect()
)
solutions[-1] = solutions[-1].to_pandas()['date_str']polars|strftime 0.313735s
polars|date→dedupe→join 0.036649sChecking Accuracy
To verify all approaches generated the same output, I checked them in a pairwise manner. If any two DataFrames are not the same, then we will observe an error.
from itertools import pairwise
print(f'{len(solutions) = }')
for s1, s2 in pairwise(solutions):
assert (s1.astype(int) == s2.astype(int)).all()len(solutions) = 7from pandas import DataFrame
df = (
DataFrame(timer.registry, columns=['description', 'timer'])
.assign(
elapsed_ms=lambda d: 1_000 * d['timer'].map(lambda t: t.elapsed),
package=lambda d: d['description'].str.extract(r'(.*)\|'),
)
.drop(columns='timer')
.sort_values('elapsed_ms', ascending=False)
)
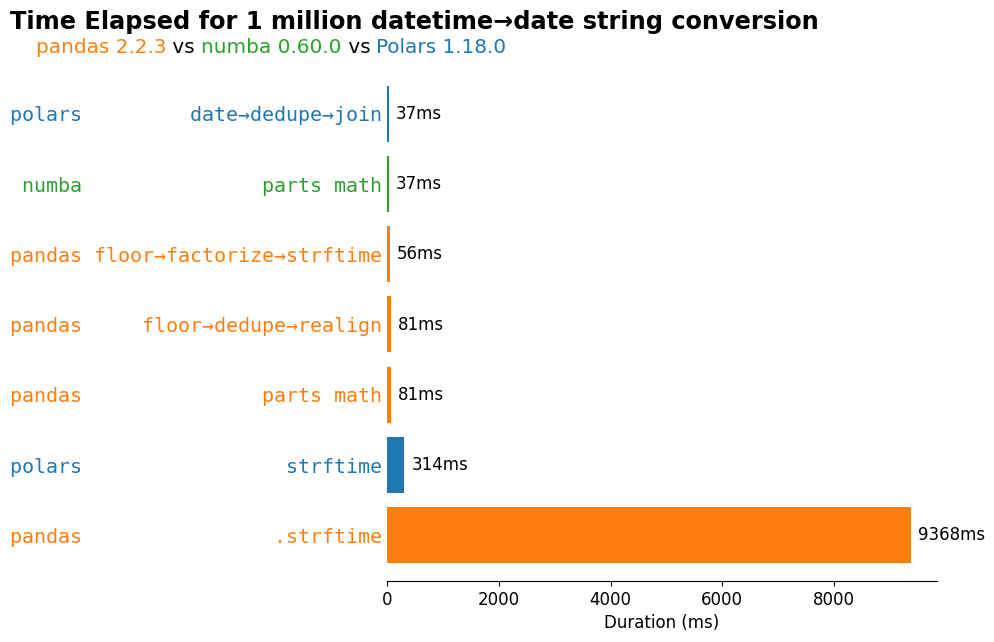
df| description | elapsed_ms | package | |
|---|---|---|---|
| 0 | pandas|.strftime | 9368.279530 | pandas |
| 5 | polars|strftime | 313.734646 | polars |
| 4 | pandas|parts math | 80.999028 | pandas |
| 1 | pandas|floor→dedupe→realign | 80.582244 | pandas |
| 2 | pandas|floor→factorize→strftime | 56.470541 | pandas |
| 3 | numba|parts math | 37.192969 | numba |
| 6 | polars|date→dedupe→join | 36.649275 | polars |
Visualize The Micro-benchmarks
%matplotlib inlinefrom matplotlib.pyplot import rc, setp
from flexitext import flexitext
import polars, pandas
rc('figure', figsize=(10, 6), facecolor='white')
rc('font', size=12)
rc('axes.spines', top=False, right=False, left=False)
palette = {
'polars': '#1F77B4FF',
'pandas': '#FF7F0EFF',
'numba': '#2CA02C',
}
ax = df.plot.barh(
x='description', y='elapsed_ms', legend=False, width=.8,
color=df['package'].map(palette),
)
ax.set_ylabel('')
ax.yaxis.set_tick_params(length=0)
ax.bar_label(ax.containers[0], fmt='{:.0f}ms', padding=5)
ax.set_xlabel(r'Duration (ms)')
ax.margins(y=0)
new_labels = []
for lab in ax.get_yticklabels():
package, _, approach = lab.get_text().partition('|')
lab.set(
text=f'{package}{approach:>25}',
color=palette[package],
size='large',
fontfamily='monospace',
)
new_labels.append(lab)
ax.set_yticklabels(new_labels)
ax.figure.tight_layout()
left_x = min(text.get_tightbbox().x0 for text in ax.get_yticklabels())
x,_ = ax.transAxes.inverted().transform([left_x, 0])
annot = flexitext(
s='<size:x-large,weight:semibold>'
'Time Elapsed for 1 million datetime→date string conversion\n'
'</>'
'<size:large>'
f' <color:{palette["pandas"]}>pandas {pandas.__version__}</>'
f' vs <color:{palette["numba"]}>numba {numba.__version__}</>'
f' vs <color:{palette["polars"]}>Polars {polars.__version__}</>'
'</>',
x=x, y=1.02, va='bottom', ha='left',
);
Wrap-Up
Seems like all tools—numba, Polars, and pandas—can tackle this problem with very similar timings for the fastest datetime→date string(ish) conversion. In this case, our manual strategies (deduplication & realignment) created the largest improvement in time, rather than the specific tool that we used.
I personally much prefer the pandas and Polars solution as I am hesitant about untested numba because the former will be much easier to maintain in the future. Let the library authors write library code.
That's it for this week! When approaching any type of optimization problem, make sure that you question the algorithm first rather than reach for unfamiliar tools just because they're marketed as "faster" alternatives.
What did you think about my approach? Let me know on our Discord. Talk to you all next week!