“Broadcasting” in Polars
Hello, everyone! Welcome back to Cameron's Corner. This week, I want to look into performance in Polars when working with multiple DataFrames. We are going to cover "broadcasting"—a term used for aligning NumPy arrays against one another—in Polars. Polars always encourages us to be explicit when aligning and working with multiple DataFrames, but there are a few different conceptual approaches we can take to arrive at the same solution. This is where today's micro-benchmark will come in. We want to find the fastest approach for this specific problem.
Premise
Say we have two LazyFrames, where one is of an undetermined length and the other has a known length of 1 (after collection). We want to be able to perform arithmetic across these two LazyFrames as in the following example:
from polars import DataFrame, col, concat
from numpy.random import default_rng
rng = default_rng(0)
df1 = DataFrame({"x": rng.integers(10, size=5)})
df2 = DataFrame({"y": -2})
(
concat([df1, df2], how='horizontal')
.with_columns(
result=col('x') * col('y').first()
)
)| x | y | result |
|---|---|---|
| i64 | i64 | i64 |
| 8 | -2 | -16 |
| 6 | null | -12 |
| 5 | null | -10 |
| 2 | null | -4 |
| 3 | null | -6 |
The approach we took above used polars.concat to combine our two DataFrames and performed an arithmetic operation between the two columns 'x' and 'y'. (Note that we used col('y').first() to notify pandas that we only want to operate on the first value in this column since the rest of the values will be null after concatenation.)
Selected Approaches
We are going to write up and benchmark the following approaches. You can see that two of the approaches revolve around using polars.concat; two revolve around using an explicit .join; and the final approach will circumvent the need for an explicit alignment operation by collecting our smaller LazyFrame first.
concat(..., how="horizontal") → col('y').first()
As seen aboveconcat(..., how="horizontal") → col('y').forward_fill()
The same as the above, but forward_fill the y column instead of selecting the first valuejoin(..., on="dummy")
Create a dummy column, all with the same value, and join on that. This will repeat the value from our small LazyFrame columns against our larger LazyFrame.join(..., how="cross")
Since we have a single row LazyFrame, we can cross-join these Frames without worrying about a cartesian product explosion. This will create the same intermediate result as the approach above.early collect
Don't worry about explicitly aligning the LazyFrames. Simply collect the smaller LazyFrame and work with those values as if they are scalars.
Performance Timing
In order to benchmark the above concepts, we are going to need some type of timer. I wrote up a quick one that lets us track multiple different timings over multiple calls. You can see how it works below:
Disclaimer: I am not concerned with repeatedly testing these timings in an exhaustive manner.
from time import perf_counter, sleep
from contextlib import contextmanager
from dataclasses import dataclass, field
from polars import DataFrame
@dataclass
class Timer:
start: float
stop: float
@property
def duration(self):
return self.stop - self.start
@dataclass
class TimerManager:
timers: list = field(default_factory=list)
@contextmanager
def timed(self, msg, verbose=True):
start = perf_counter()
yield
stop = perf_counter()
self.timers.append(
(msg, timer := Timer(start, stop))
)
if verbose:
print(f'{msg} elapsed {timer.duration * 1000:.2f}ms')
def to_df(self, schema=['message', 'start', 'stop', 'duration[s]']):
return DataFrame(
data=[
(msg, t.start, t.stop, t.duration)
for msg, t in self.timers
],
schema=schema,
orient='row'
)
timer = TimerManager()
with timer.timed('test ①'):
sleep(.1)
with timer.timed('test ②'):
sleep(.3)
timer.to_df()test ① elapsed 100.08mstest ② elapsed 300.07ms| message | start | stop | duration[s] |
|---|---|---|---|
| str | f64 | f64 | f64 |
| "test ①" | 1.0537e6 | 1.0537e6 | 0.100078 |
| "test ②" | 1.0537e6 | 1.0537e6 | 0.300074 |
Setup
We're going to create a fairly large LazyFrame to work with: 1,000,000 rows, including two unique columns in our single-row LazyFrame.
from polars import LazyFrame, col
from numpy.random import default_rng
rng = default_rng(0)
df1 = LazyFrame({"x": rng.integers(100_000, size=1_000_000)})
df2 = LazyFrame({"y1": -2, "y2": 4})
timer = TimerManager()
results = []
display(
df1.head(5).collect(),
df2.collect(),
)| x |
|---|
| i64 |
| 85062 |
| 63696 |
| 51113 |
| 26978 |
| 30782 |
| y1 | y2 |
|---|---|
| i64 | i64 |
| -2 | 4 |
concat → first
from polars import concat
with timer.timed('concat → first'):
combined = concat([df1, df2], how="horizontal")
res = combined.select(
col("x") - col("x") * col("y1").first() * col("y2").first()
).collect()
results.append(res) # save result for later comparisonconcat → first elapsed 8.72msconcat → forward_fill
with timer.timed('concat → ffill'):
combined = concat([df1, df2], how="horizontal")
res = combined.select(
col("x") - col("x") * col("y1").forward_fill() * col("y2").forward_fill()
).collect()
results.append(res)concat → ffill elapsed 17.69msjoin on dummy
with timer.timed('join[on=dummy]'):
joined = (
df1.with_columns(dummy=1)
.join(df2.with_columns(dummy=1), on="dummy")
)
res = joined.select(
col("x") - col("x") * col("y1") * col("y2")
).collect()
results.append(res)join[on=dummy] elapsed 25.06mscross join
with timer.timed('join[cross]'):
res = (
df1.join(df2, how="cross")
.select(col("x") - col("x") * col("y1") * col("y2"))
.collect()
)
results.append(res)join[cross] elapsed 14.91msearly collect
with timer.timed('early collect'):
early = df2.collect()
res = df1.select(
col("x") - col("x") * early["y1"] * early["y2"]
).collect()
results.append(res)early collect elapsed 5.52msVerification
Before we do anything with these timings, we should ensure that they all produce the same answers. Then we can look at a comparison of their execution times.
from itertools import pairwise
for x, y in pairwise(results):
assert x.equals(y)
df = (
timer.to_df()
.select('message', col('duration[s]').round(4))
.sort('duration[s]')
)
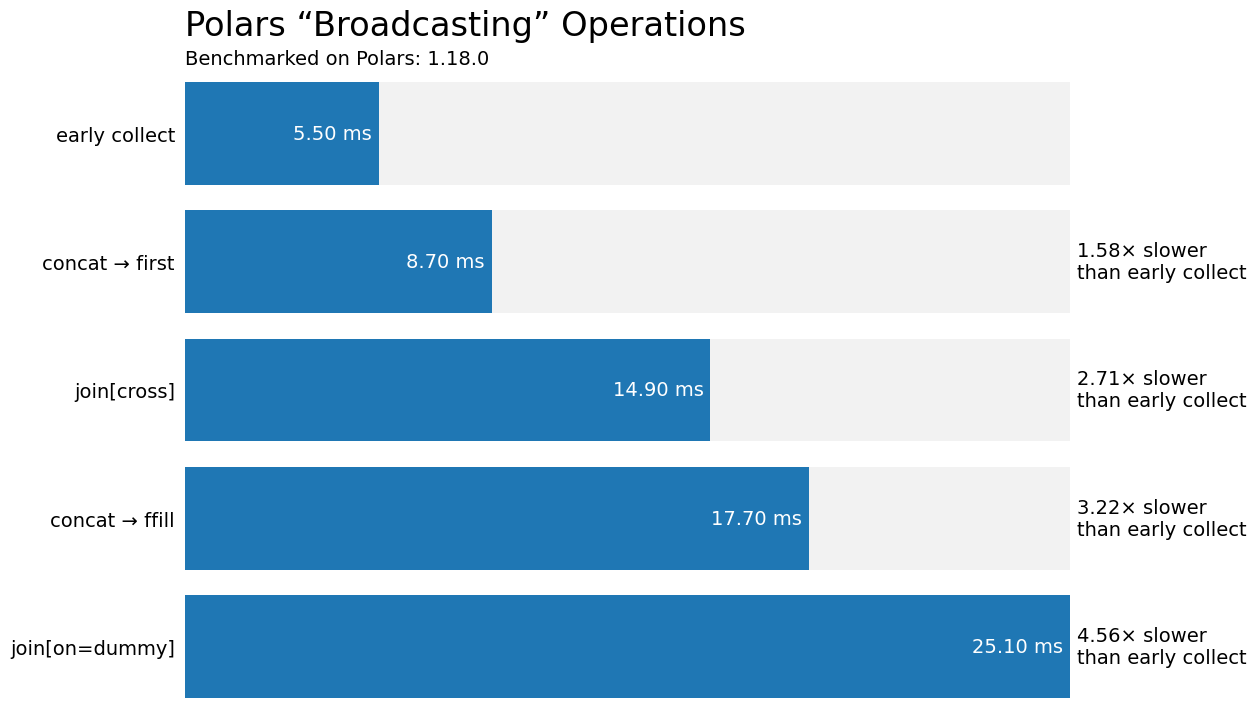
df| message | duration[s] |
|---|---|
| str | f64 |
| "early collect" | 0.0055 |
| "concat → first" | 0.0087 |
| "join[cross]" | 0.0149 |
| "concat → ffill" | 0.0177 |
| "join[on=dummy]" | 0.0251 |
Visual Comparison
But what fun is a simple numeric comparison? If we're benchmarking, we can create a data visualization to put these numbers into perspective. Let's make a horizontal bar chart comparing the duration of these execution times.
%matplotlib inlinefrom matplotlib.pyplot import rc, subplots
from polars import __version__ as pl_version
rc('font', size=14)
rc('axes.spines', top=False, right=False, left=False, bottom=False)
rc('ytick', left=False)
rc('xtick', bottom=False, labelbottom=False)
unit_label, unit_mul = 'ms', 1_000
duration = df['duration[s]'] * unit_mul
fig, ax = subplots(figsize=(12, 8), facecolor='white')
elapsed_bc = ax.barh(df['message'], duration)
compare_bc = ax.barh(
df['message'], duration.max(), zorder=0, color='gray', alpha=.1
)
ax.invert_yaxis()
ax.margins(y=0)
for elapsed, comp in zip(elapsed_bc, compare_bc):
ax.annotate(
f'{elapsed.get_width():.2f} {unit_label}',
xy=(1, .5), xycoords=elapsed,
xytext=(-5, 0), textcoords='offset points',
ha='right',
va='center',
color=ax.get_facecolor(),
)
if elapsed.get_width() > duration.min():
ax.annotate(
f'{elapsed.get_width()/duration[0]:.2f}× slower\nthan {df[0, "message"]}',
xy=(1, .5), xycoords=comp,
xytext=(5, 0), textcoords='offset points',
ha='left',
va='center',
)
subtitle = ax.annotate(
f'Benchmarked on Polars: {pl_version}',
xy=(0, 1), xycoords=ax.transAxes,
xytext=(0, 10), textcoords='offset points',
va='bottom',
)
title = ax.annotate(
f'Polars “Broadcasting” Operations',
xy=(0, 1), xycoords=subtitle,
xytext=(0, 5), textcoords='offset points',
va='bottom',
size='xx-large',
)
Wrap-Up
And there you have it: a quick micro-benchmark comparing operations in Polars. There is definitely a large difference in these timings. Even though an optimizer takes a pass on your query, there are barriers that it simply cannot overcome that require a better implementation on the human-code side of the problem.
What do you think about working with multiple dataframes in Polars? How would you implement it in your code? Let me know on the DUTC Discord server.
Talk to you all next week!