All Posts
pandas.concat, explained.
- 10 July 2024
Hello, everyone! Welcome back to Cameron’s Corner. This week, I want to tackle
a pandas question I received concerning the different ways to combine pandas.DataFrames.
Today, I’ll focus on pandas.concat, since we have
covered DataFrame merges quite thoroughly in previous weeks. Specifically, we’ll take a look at
DataFrame Inequality Joins, DataFrame Joins & Sets and DataFrame Joins & MultiSets.
In pandas, we have three explicit ways to combine DataFrames:
DataFrame Inequality Joins
- 10 July 2024
Hello, and welcome back to Cameron’s Corner! This week, I want to follow up on two blog posts from a couple months back that discussed DataFrame Joins & Sets and DataFrame Joins & MultiSets.
Instead of speaking more about equality joins, I want to talk about inequality joins. These are a special table join operation that handles conditions when keys don’t match up perfectly, particularly when working with continuous (non-categorical) data.
Flexibility & Ergonomics
- 26 June 2024
Hi all, welcome back to Cameron’s Corner! This week, I want to talk about flexibility and ergonomics.
Oftentimes, we want to write code that is flexible to adapt to the ever-changing problems we are presented with. This often means that we have to write code that anticipates different formulations of an existing business problem. On the other hand, we should also endeavor to write code that is readily usable by our colleagues or other end-users. While these forces—flexibility and ergonomics—may feel like they pull in opposite directions, we should always strive to find a solution where these ideas work in tandem. The most generalized approach we can take to satisfy this is to design APIs with two primary layers of abstraction:
A FlagEnum Categorical in pandas
- 19 June 2024
Hi all, welcome back to Cameron’s Corner! This week, I want to explore the encoding of combinatoric sets (from a
limited pool) inside a pandas.DataFrame. In more colloquial terms, I want
to explore the following example:
We have a catalog of programming articles & videos (entities).
Tabular Group By Sets
- 12 June 2024
Hi all, welcome back to Cameron’s Corner! This week, I want to replicate some convenient analytical functionality from DuckDB in both pandas and Polars.
Before we get started, I want to let you know about our upcoming public seminar series, “(Even More) Python Basics for Experts.” Join James in this covering (even more) Python basics that any aspiring Python expert needs to know in order to make their code more effective and efficient. He’ll tackle what’s real, how we can tell it’s real, and how we can do less work.
pandas & Polars: Window Functions vs Group By
- 05 June 2024
Welcome to this week’s Cameron’s Corner! Before we get started, I want to let you know about our upcoming public seminar series, “(Even More) Python Basics for Experts.” Join James in this three-session series covering (even more) Python basics that any aspiring Python expert needs to know in order to make their code more effective and efficient. He’ll tackle what’s real, how we can tell it’s real, and how we can do less work.
This week, I want to dive back into “window” and “group by” operations. This time, instead of focusing on the SQL syntax, we’ll cover my two favorite DataFrame libraries, pandas and Polars, to discuss the differences in their APIs.
Faster strftime
- 29 May 2024
Welcome back to this week’s Cameron’s Corner! Before we get started, I want to let you know about our upcoming public seminar series, “(Even More) Python Basics for Experts.” Join James in this three-session series about (even more) Python basics that experts need to make their code more effective and efficient. He’ll tackle what’s real, how we can tell it’s real, and how we can do less work.
On to the topic at hand. I wanted to tackle a fun pandas optimization problem, focusing on converting datetime objects to their date counterparts. For this problem, I did take it “head on,” meaning I did not inquire why the end user wanted this output, just performed some benchmarking on their existing approaches and threw in a couple of my own.
Decorators: Registration Pattern
- 22 May 2024
Hello, everyone! Before we get started, I want to let you know about our upcoming public seminar series, “(Even More) Python Basics for Experts.” Join James in this three-session series about (even more) Python basics that experts need to make their code more effective and efficient. He’ll tackle what’s real, how we can tell it’s real, and how we can do less work.
Okay, on to this week’s post!
Working With Files Deep in Your Code
- 15 May 2024
Hello, everyone! Before we get started, I want to let you know about our upcoming public seminar series, “(Even More) Python Basics for Experts.” Join James in this three-session series about (even more) Python basics for experts. He’ll tackle what’s real, how we can tell it’s real, and how we can do less work.
As you may already know, we frequently train corporate teams on topics such as introduction to Python, advanced Python, API design, data analysis, and much more! Our trainings always involve custom curriculum which we tailor to the needs of the team and balance with the expectations of management.
Tables: Window Functions vs Group By
- 08 May 2024
Hello, everyone! This week, I want to dive into “window” and “group by.” What’s the difference? When should you use one over the other? Let’s take a look.
Both window and group by functions are used to perform operations across a subset of rows of a table. These rows are subsetted based on a unique grouping of values within a column.
When the .index is convenient
- 01 May 2024
The blazingly-fast DataFrame library, Polars, has a huge conceptual difference from the
DataFrame veteran, pandas: pandas is
ALL about working with a consistent index, whereas Polars forces individuals
to work more explicitly using joins.
I came across a question on Stack Overflow that provided a great example of the benefits of working in an index-aligned way.
DataFrame Joins & MultiSets
- 24 April 2024
There is a fairly strong relationship between table joins and set theory. However, many of the table joins written in SQL, pandas, Polars and the like don’t translate neatly to set logic. In this post, I want to clarify this relationship (and show you some Python and pandas code along the way).
Last week, I covered unique equality joins which describes the simplest scenario in which sets and table join logic completely overlap. This parallels the idea that table joins can be represented with Venn diagrams. This week, I want to show where this mode of thinking tends to fall flat.
DataFrame Joins & Sets
- 17 April 2024
There is a fairly strong relationship between table joins and set theory. However, many of the table joins written in SQL, pandas, Polars and the like don’t translate neatly to set logic. In this blog post, I want to clarify this relationship (and show you some Python and pandas code along the way).
Let’s start with unique equality joins as they are the prototypical representation of a table-join operation. This is also the only type of join that neatly falls into standard set theory (without expanding to multi-sets, which we’ll discuss later).
Parsing Unconventional Text
- 10 April 2024
Hey everyone! I’m back to playing around with Polars again and wanted to share a fun problem I came across on Stack Overflow. In this problem, the OP had some raw textual data in a key-value paired format. However, this format is not one that is commonly supported, like JSON. This means we get to write a custom parser!
We need to read in this data and create a column for each of these fields, appropriately filling in null values for any row that is missing a field that is previously or later defined.
Intentional Visualizations
- 27 March 2024
Hello, everyone! This week, I want to discuss the often-overlooked exploratory charts.
I often speak to a dichotomy of purposes whenever I discuss data visualization. These purposes are designed to help organize our thoughts about both why and how we should visualize our data in the first place. The reasons one might reach for a visualization are:
Timing DataFrame Filters
- 20 March 2024
Hello, everyone! I wanted to follow up on last week’s blog post, Profiling pandas Filters, and test how Polars stands up in its simple filtering operations.
An important note: these timings are NOT intended to be exhaustive and should not be used to determine if one tool is “better” than another.
Profiling pandas Filters
- 13 March 2024
Hello, everyone! For Cameron’s Corner this week, I wanted to spend some time differentiating between various filtering
operations in pandas. Specifically, I wanted to test out operations on
a DatetimeIndex for working with slices of datetime values.
Let’s do some quick timings for each of these approaches. I’ve ordered them by what my intuition tells me will be slowest to fastest:
Python Set vs Pandas.Index
- 06 March 2024
For the past few weeks, I have been meeting with some fantastic clients in
one-on-one sessions to cover the core Python and pandas skills needed to perform
rapid data analysis. We have discussed a variety of topics, but this week has been one
of my favorites because we are doing a deep dive into pandas. Of course, the
framing for pandas is all about the Index, so I decided to keep it light and
ensure we tie it back to some core Python concepts.
When discussing the Index in pandas, I always find it useful to contrast it against
a Python built-in that exhibits some similar behaviors: the set. This week,
I want to focus on each of these data structures to understand where they overlap, their differences, and the lessons they can teach us.
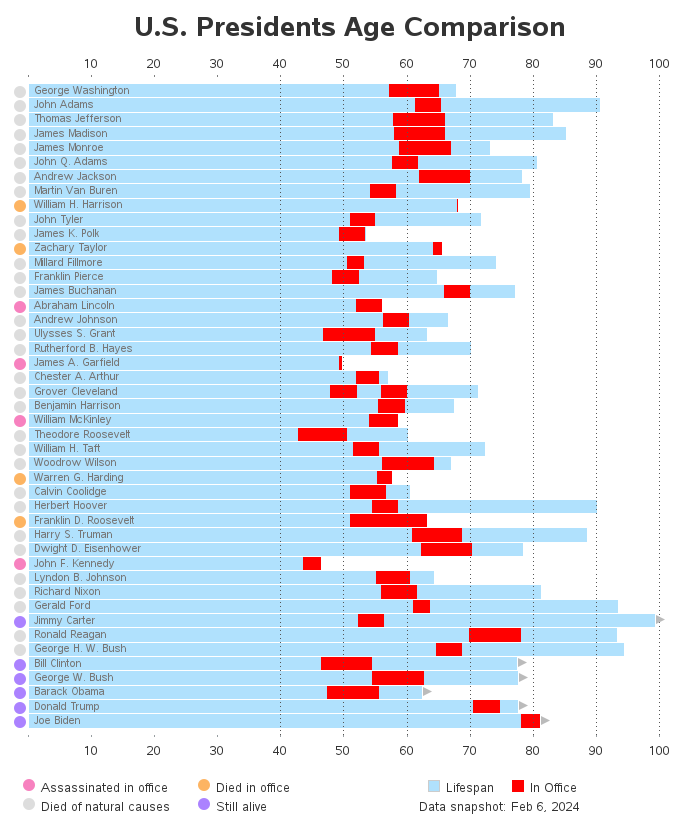
United States President’s Age
- 14 February 2024
Welcome to Cameron’s Corner! This week, I want to recreate a chart from a post on r/dataisbeautiful by u/graphguy.
Polars Expressions on Nested Data
- 07 February 2024
Welcome back to Cameron’s Corner! This week, I wanted to share another interesting question I came across on Stack Overflow: “How to add numeric value from one column to other List colum elements in Polars?”.
Speaking of Polars, make sure you sign up for our upcoming µTraining, “Blazing Fast Analyses with Polars.” This µtraining is comprised of live discussion, hands-on problem solving, and code review with our instructors. You won’t want to miss it!
Tiered Bar Chart in Matplotlib
- 31 January 2024
Welcome back to Cameron’s Corner! This week, I wanted to share an answer I posted on Stack Overflow to a question entitled Create a bar chart in Python grouping the x-axis by two variables. This question sought to create a grouped bar chart, but also have hierarchical x-tick labels.
The question effectively asked how to create a chart like this:
Good pandas means good Python
- 24 January 2024
Welcome back to Cameron’s Corner! This week, I want to talk about the intersection of Python and pandas. I often hear from other teachers that it is easiest to teach skills that will help students get “up and running.” Unfortunately, this often translates to “let’s teach the pandas API.” This leads to many roadblocks down the line caused by an extremely superficial understanding of how to think about pandas operations or how to best leverage Python to lean into your pandas tasks.
So, let’s take a look at a data-cleaning example, where, while possible, working through pandas will be clumsy.
Polars: Groupby and idxmin
- 17 January 2024
Welcome back to Cameron’s Corner! It’s the third week of January, and, instead of talking about graphs, I want to take a dive into Polars. I recently addressed a question on Polars’ Discord server, diving into the different ways to perform an “index minimum” operation across groups.
Sure, there’s a built-in Expression.idx_min(), but it operates a little differently than it does in pandas. Let’s take a look:
Counting paths in pandas & networkx
- 10 January 2024
Welcome back to Cameron’s Corner! It’s the second week of January, and I’m already here to talk about graphs. No, not the kind we make in Matplotlib, but network graphs! This blog post was inspired by a project I’ve been working on: counting the number of indirect connections between two non-adjacent nodes in a bipartite graph.
In graph theory terms, a graph is bipartite if its nodes are segmented into discrete levels, where nodes from one level connect to nodes from another level but never within the same level. Here is an example from Wikipedia of what a complete bipartite graph might look like:
Don’t Use This Code’s top 10 resolutions of 2024 for YOU!
- 03 January 2024
Hello everyone and welcome to the first Cameron’s Corner of the New Year! Before we get too far, I wanted to just do a quick recap of our year.
In 2023, Don’t Use This Code…
Visualizing Temperature Deviations
- 20 December 2023
This week, I wanted do some data manipulation in Polars and recreate a data visualization I came across a while ago from the Python Graph Gallery, titled “Area Chart Over Flexible Baseline.” I liked this type of chart because it highlights an aggregate measure of interest that is easy to understand and demonstrates how much that measure deviates from some context. In this case, the chart communicates how much the temperature across a given year in a specific city has deviated with respect to historical aggregations.
Most free historical weather data APIs that I have encountered consume latitude and longitude coordinates instead of addresses. However, to make the code I am using here, I am going to use an address API to query the location of a given city/state. We can use the response from this API to feed into the weather API. This makes it very trivial to query different locations across the world!
DataFrame Value Membership Testing
- 13 December 2023
This week, I received a great question on our Discord Server about finding strings within a list in a pandas.Series.
But, before I get started, I want to invite you to our upcoming µtraining (“micro-training”) that we will be hosting on December 19th and 21st. This unique training format ensures direct interaction with instructors and your peers, providing practical insights and immediate problem-solving guidance.
Playing Scrabble with Xarray
- 06 December 2023
Welcome to Cameron’s Corner! In my last blog post, I explored how to use index-alignment to solve some simple Scrabble problems. Today I want to do the same using Xarray!
But, before I get started, I want to invite you to our upcoming µtraining (“micro-training”) that we will be hosting on December 19th and 21st. This unique training format ensures direct interaction with instructors and your peers, providing practical insights and immediate problem-solving guidance.
Playing Scrabble Faster
- 22 November 2023
Welcome to Cameron’s Corner! This morning, I gave a seminar on coding word games like an expert! I talked about prototyping the game of Scrabble, and wanted to share some additional thoughts I had after the presentation.
But, before I get started, I want to invite you to our next (and final!) seminar in our Python: How the Experts Do It series, “Battleship: An Expert’s Approach to Seemingly Simple Games.” Join us as we embark on the Battleship journey, leveraging Python’s object-oriented prowess to design and implement this iconic game.
Playing (more) Tic-Tac-Toe
- 15 November 2023
Hello everyone and welcome back! Last week, we discussed my live-coded approach (and improvements!) to the game of Tic-Tac-Toe. This week, I wanted to see how flexible my approach is going to be.
But, before we get into it, make sure you register for our next expert lab, “Word Games: An Expert’s Approach to Seemingly Simple Games.” During this session, we’ll unravel the mysteries of word unscrambling in Jumble and challenge ourselves with the strategic wordplay of Scrabble. You’ll witness firsthand how Python’s powerful string manipulation features and other data structures can simplify coding of these games.
Playing Tic-Tac-Toe
- 08 November 2023
Hello, everyone! This week, I held a seminar where I live-coded the game of tic-tac-toe based on some constraints from a client. I wanted to share with you what the final version of this code would look like after a round of review.
Before we get started, I want to tell you about my upcoming seminar with a similar theme, “A Python Expert’s Approach to Rock, Paper, Scissors.” During this seminar, we’ll dissect the game’s rules, design custom Python functions, and explore the strategic thinking behind this simple yet captivating game. We’ll start with the basics, modeling the game using core Python data structures, and then quickly progress to incorporate more advanced features.
Visualizing Dropped Video Frames
- 18 October 2023
Welcome back, everyone! This week on Cameron’s Corner, I’m going to get a bit creative. I want to take you through my process for optimizing the (many) Python instruction videos I make.
But, first, I want to let you know about my upcoming seminar, “Arrow & In-Memory Data”! This seminar is designed to provide attendees with a comprehensive understanding of Arrow and its interface with PyArrow, a Python library for working with Arrow data structures.
Dataviz Makeover
- 27 September 2023
Hello, everyone! Two weeks ago, I re-created a data visualization I found online and I had so much fun that I decided to do it again! This week I’m recreating another visualization from Data is Beautiful on Reddit.
But, before we get started, I want to let you know about my seminar coming up next week, “Understanding Textual,” which is part of our Investigating the Hype seminar series! This series offers an in-depth exploration of different software that will help make your code more efficient. We’ll dive into Textual, DuckDB, Polars, and Apache Arrow and see if they’re really worth all the hype! I have some great things planned, so you won’t want to miss it!
Business Jet Demand In North America
- 13 September 2023
Hello, everyone! This week, I’m recreating a visualization from Data is Beautiful on Reddit.
Before I get started, I want to remind you of the final part of the Correctness seminar series, “How do I Check that my Data and Analyses are Correct?”. We’ll join James Powell as he unravels the art of performing data analysis with confidence in Python. Explore the challenges of data analysis pipelines and learn how to write robust analyses that have observable hooks. Discover methods for data cleaning and validation to avoid silent errors that can pollute your results.
Homogenous Computations: Thoughts on Generator Coroutines
- 06 September 2023
Hello, everyone and welcome back to Cameron’s Corner! This week, I have a treat. We received a fantastic question in our Discord Server—which you should join if you haven’t yet—about the usage of a generator coroutine
in Python. Specifically, the question sought to disambiguate the call of __next__
and .send(None) on a generator instance.
Before I get started, I want to remind you about the seminar coming up tomorrow, September 7th, titled, “How Do I Write “Constructively” Correct Code with Metaclasses & Decorators?” Join James Powell as he delves into the powerful concept of leveraging Python’s object construction mechanism to enforce code correctness. Discover how metaclasses, decorators, and other language features can be used to validate and coerce input data, define selective object hierarchies, and implement abstract base classes.
Time-series Alignment & Viz
- 16 August 2023
Hey all, welcome back to Cameron’s Corner. This week, we are taking an even deeper dive into our use of Gantt charts to represent binary signals. We’ll certainly cover visualizing these data but I also want to get into some of the signal processing tricks we can apply to align multiple signals against each other.
Speaking of visualization, don’t forget to join me on August 17th for a FREE seminar, “Visualizations: Exploratory → Communicative,” where I’ll demonstrate how to harness the power of Matplotlib to create impactful data visualizations. From exploratory analysis to communicative visualizations, I’ll guide you through uncovering insights and effectively conveying your message. Discover the techniques to profile your audience, focus their attention, and deliver precise and compelling data visualizations.
Gantt Charts in Matplotlib
- 09 August 2023
Hey everyone! Welcome to this week’s entry into Cameron’s Corner. This week, I’ve been busy teaching courses, working on some exciting TOPS updates, and helping James prep for a FREE popup seminar coming up on August 10th, “Solving Uno… the Right Way!” I can’t wait for you to see what he in store.
For today’s post, I wanted to share a fun consulting project I’m working on which involves visualizing binary signals (on/off states) across multiple devices. These types of data are often visualized using stateful lines where they rapidly increase to a value of 1 to indicate an “on” state or drop to 0 to indicate an “off” state. However, for the volume of data that we are working with, the vertical lines become nearly impossible to track because there is no ramp-up in our signal.
Edward Tufte’s NYC Weather In Bokeh
- 19 July 2023
Hello, everyone! Welcome back to Cameron’s Corner. This week, I wanted to expand upon using Bokeh to visualize the weather by revisiting the Edward Tufte NYC Weather in 2003 visualization I recreated in Matplotlib. Except, this time, I want to see if Bokeh is up to the challenge.
All of the data & set up will be identical to the previous post from March, so we can gloss over those details. If you’re up to date, feel free to skip down to the Recreating Tufte in Bokeh section.
Exploring Weather with Bokeh!
- 12 July 2023
Hey everyone! This probably comes as a surprise, but I’m on another data-viz kick! This week, I wanted to share with you a way to interact with a few years of daily timeseries data.
We’ll be revisiting a fun dataset: daily temperature readings from New York City! This historical dataset has decades of data. However, for our purposes, I wanted to limit it to five years’ worth and visualize daily data (maximum and minimum temperatures) while allowing the ability to interactively to zoom in/out on any specific set of dates.
Don’t Forget About the Index!
- 05 July 2023
This week, we have another question from StackOverflow. The question this week features a pandas problem that looks
tricky on the surface. However, it becomes quite straightforward once your remember to not forget about the .index.
Specifically, in this problem, we had a data manipulation problem:
Why is DataFrame.corr() so much slower than numpy.corrcoef?
- 28 June 2023
Hey all! This week, I encountered a question that reminded me of our upcoming Performance seminar series.
I responded to this question on StackOverflow in which the author noted that calling pandas.DataFrame.corr() was much slower than calling
numpy.corrcoef with the following result:
When do I Write a Function?
- 21 June 2023
Hey all, this week I wanted to visit a topic that comes up across many of the courses that we teach:
When do I write a function?
Fix those overlapping labels!
- 14 June 2023
Hello, everyone! Welcome back to Cameron’s Corner! This week, I want to resolve a common frustration I encounter in Matplotlib: overlapping labels.
Ever since Matplotlib 3.4, we have had an easy Axes.bar_label to quickly introduce labels on top of our bars.
The example is fairly straightforward and nicely highlights centered labels.
Star Trader & Matplotlib: A Live-coded Session
- 07 June 2023
Welcome to Cameron’s Corner! This week, I wanted to reflect a on a pop-up seminar I held where I demonstrated some live-coded Matplotlib data visualizations.
In this session, we talked about planning an effective data visualization. My biggest recommendation once you understand the data and have an idea of what you want to convey is to not jump straight into creating visualizations. But instead, plan out your visualization using simple drawing tools—in this case, I chose PowerPoint as it was already installed on my machine. This lets me easily plan and adjust a layout of multiple plots and iterate on my design.
Bokeh: Interactive plots in static HTML
- 31 May 2023
Welcome back, everyone! Before I get started, I want to let you know about an upcoming FREE seminar: “On the Spot, Live-Coded Data Visualizations,” where I’ll be live-coding data visualizations that YOU pick for me! You won’t want to miss it!
Last week, I shared a primer on Bokeh. This week, I wanted to take things up a notch and share some
of the more powerful features Bokeh has beyond its core components. Sure, we can make
figures and add Glyphs to them, but we can also make a completely responsive
data visualization with just a few lines of JavaScript.
Working With Bokeh Models
- 24 May 2023
Hey all! This week, I want to talk a bit about one of my favorite web-friendly data visualization tools: Bokeh. I’ll be delivering a FREE seminar on Bokeh on Friday, May 26th, and you won’t want to miss it! Register here!
Bokeh is a very powerful library that boasts tight coupling between Python and javascript to create interactive web-browser-based data visualizations.
A Cheat Sheet for your Bash
- 17 May 2023
Hey all! This week, I want to talk a bit about a new love of mine: shell.
While Python was my first programming language, over the years, I have
been doing more and more things in shell. I specifically use Bash, and I always
seemed to reach for Google whenever I had to do anything remotely complex and beyond the basics.
Get Rid of Those Legends!
- 03 May 2023
Hey everyone! I’m back with some more data viz! This past week, I received a question about labeling a line chart in Matplotlib without a legend. While there are a few examples demonstrating this idea, I wanted to write up a quick blog post on the topic.
At DUTC, we advocate for the removal of legends in charts whenever possible. Legends cause “jumps” of attention for your audience, meaning that they need to rapidly glance back and forth between data and legend to make sense of the chart.
Useful Multiple-Axis Plots
- 26 April 2023
Welcome back to Cameron’s Corner! This week, in preparation for my upcoming seminar, Intro to Bayesian Stats in Python, we’re diving into some (more) data visualization!
I wanted to talk about a question I recently received about Matplotlib, “How do you create a dual-axis chart that conveys unit information?” In my opinion, this is a context where a dual-axis chart is usable and won’t mistakenly mislead your audience. Instead of using a second axis to communicate data about a different series of data, we can use a second axis to communicate supplementary information about a single series of data.
Make Your Naive Code Fast with Polars
- 19 April 2023
Welcome back to Cameron’s Corner! This week, I presented a seminar on the conceptual comparison
between two of the leading DataFrame libraries in the Python Open Source
ecosystem: the veteran pandas vs the newest library on the block, Polars.
Polars has been around for over a year now, and since its first release, it has gained a lot of traction. But, what is all of the hype about? Is it some “faster-than-pandas” benchmark? The expression API? Or something else entirely? In my opinion, I’m still going to be using pandas, but Polars does indeed live up to its hype.
Hierarchical Bar Charts in Matplotlib
- 12 April 2023
If you’ve heard me talk about bar charts in Matplotlib, then you’ve probably heard
me say that the thing I enjoy the least is creating grouped/hierarchical
bar charts. Typically, I dish this responsibility over to methods/packages like
pandas or seaborn, but, this week, I wanted to share my favorite fun way to create a grouped barchart in pure Matplotlib.
You may wonder what makes grouped bar charts tricky to create and the answer lies in a core assumption: all data is continuous. That’s right, Matplotlib has no notion of an inherently categorical Axis, despite methods like Axes.bar making it seem like our x-axis is categorical. While this approach is very flexible, it also means that, if we want to create grouped bar charts, we need to manually track the positions of each of our categories & subcategories. While this doable, it can be tedious, which is one of the reasons tools like seaborn exist.
Parallelization & Concurrency in Python
- 05 April 2023
Welcome back to this week’s blog post! Today, I wanted to revisit a post I wrote one year ago today on concurrency in Python, covering utilities like multiprocessing, threading, and asyncio.
Here, we have three very different libraries that all share somewhat similar functionality, but I often run into questions about when one should reach for any of these libraries. I also hear a lot of discussion about Python’s notorious global interpreter lock (GIL). Before I go into the mechanics of these topics, I want to ensure we’re all on the same page with my favorite metaphor on synchronous vs concurrent vs parallel code: the kitchen.
A Funnel Chart in Matplotlib
- 29 March 2023
Hey there again! This week, I wanted to share a small snippet of what I will cover in my seminar “My Matplotlib can beat up your Matplotlib” on March 30th.
This seminar focuses on creating plots that are not directly offered by Matplotlib—or even other high-level API’s like seaborn (though admittedly plotly does
have many of these plots). We’re not talking about bar charts or box plots, we’re
talking about “funnel charts,” “tree diagrams,” “sunbursts,” “waffle charts,”
and “parallel coordinates/categories.” If you don’t want to install a third-party
dependency just to create a plot, then I’ll have you covered in the seminar! In addition to highlighting these varied chart types, I will also cover the Matplotlib concepts you need to create truly out-of-the-box charts.
Tufte Weather In Matplotlib
- 08 March 2023
Hello, everyone! Welcome back to Cameron’s Corner. This week, I want to dive into a topic of particular and personal interest to me: the origins of data visualization. In fact, I’m so passionate about it, I’ll be hosting a seminar on March 17th, “Spot the Misleading Data Visualization!”
Edward Tufte is one of the pioneers of modern-day data visualization. In his work, he is brilliantly able to distill core concepts that can then be applied to nearly any form of visual communication. If you aren’t familiar with his work and are interested in the topic of data visualization in general, I highly recommend Tufte’s book, “The Visual Display of Quantitative Information”.
What the Index?
- 01 March 2023
Hello, world! My schedule is jam-packed this week getting ready for my upcoming seminar, “Spot the Lies Told by this Data,” but even that can’t take me away from Cameron’s Corner! This week, I want to discuss my old friend, the Index.
I’ve taught pandas to numerous colleagues and clients, and the most important
lesson to learn when working with this tool is to always respect the Index.
Working With Slightly Messy Data
- 22 February 2023
Hello, everyone! This week, I want to discuss working with real-world datasets. Specifically, how it’s common (and even expected) to encounter a number of data quality issues.
Some common questions you want to ask yourself when working with a new dataset are…
Dealing With Dates in pandas - Part 3
- 15 February 2023
Welcome back, everyone!
In my previous post, we discussed how we can work effectively with datetimes in pandas, including how to parse datetimes, query our dataframe based on datetimes, and perform datetime-aware index alignment. This week, we’ll be exploring one final introductory feature for working with datetimes in pandas.
Dealing With Dates in Pandas - Part 2
- 08 February 2023
In my previous post, we discussed how we can approach date times in pandas as well
as the metaphors used by the library and the differences between absolute time and
calendar time (also referred to as relative time).
This week, we’ll dive a little bit deeper into the functionality that pandas has
to offer when dealing with time series data, covering topics like:
Dealing With Dates in Pandas - Part 1
- 01 February 2023
So how do we work with dates and times in pandas? Well if we need to ensure our
operations are as performant as possible we’ll need to reach into
pandas restricted computation domain, and that means using its objects and
playing by its rules.
Fortunately, the metaphors we’ve discussed about date times along the way still hold
Dealing With Dates in Python - Part 2
- 25 January 2023
Hello, everyone! Welcome back to Cameron’s Corner! This week, I want to continue our discussion of datetimes in Python. Last time, we established a dichotomy of date usages. We have things that represent a…
point-in-time
Dealing With Dates in Python - Part 1
- 18 January 2023
Welcome back to Cameron’s Corner! This week, I want to get our hands on some code and talk about some of the approaches for dealing with datetimes in Python. Additionally, I want to discuss some common considerations you’ll need when implementing dates and datetimes in your own code. Let’s dive in!
A datetime is a specific point-in-time, referring to an instance. As the name suggests, these typically contain both a date and a time component: the date is some combination of year, month, and day, and the time is some combination of hours, minutes, and seconds, down to some pre-defined level of specificity.
DUTC in 2023
- 11 January 2023
Happy 2023, everyone, and happy first Cameron’s Corner of the year! To kick things off, we already have an exciting lineup of courses planned as well as some tweaking of our previous courses to provide more polished content and a smoother experience for you all.
This year, we plan to focus heavily on the impact our trainings have on your career. With our audience in mind, we are working on more micro-training courses designed to demonstrate applicable programming skills and modes of thinking. So far we have announced “Design APIs your Users Love: Better Code-Sharing & API Design” to help formalize your learning of programming concepts that are often “learned on the job.”
Cassino Capstone
- 21 December 2022
In our latest micro-training, “Good→Better→Best Python,” we discussed numerous in-depth examples of object-oriented programming in Python, various applications, and general guidance on what features of object-oriented programming you should use and when you might code yourself into a corner.
This was our first micro-training session to include an additional “Capstone Project” session; an additional ticket tier that offers a three-hour, interactive and hands-on session in which a small group of attendees take the resulting code written in the lab sessions and extended it into a full-fledged web app suitable for showing to current or prospective employers and colleagues.
Object Orientation & Update Anomalies
- 14 December 2022
In our latest micro-training, “Good→Better→Best Python,” we’re talking about object orientation and approaches people take when using it in Python.
(If you’re not already signed up for “Good→Better→Best Python,” it’s not too late! You can join our next workshop on Friday, December 16th by registering here. If you purchase a ticket, we’ll bring you up to speed with a recording from the first workshop along with the notes/work problems to review.)
Matplotlib: Arbitrary Precision
- 07 December 2022
It’s no secret that matplotlib is one of my favorite tools in Python (sorry, pandas, I promise you’re a close second). But, I’m not sure if I’ve shared why I think matplotlib is such a great tool. I don’t love it because of its redundant APIs or simply because I’m familiar with it, I think matplotlib is a great tool because it has near-infinite flexibility. I refer to this as “arbitrary precision” as you can be as precise or imprecise as you want.
Want to put a Polygon in some arbitrary location?
Statistical Models from formulas
- 30 November 2022
This week, I taught a course on statistical modeling in statsmodels. For those of you who have never used or heard of this Python package, it began as a subpackage in scipy called scipy.models. However, as it grew in size and complexity, it was removed from scipy, and then it became its own package, statsmodels.
As a package, it is a great way to carry out statistical modeling as it
provides a great deal of model introspection right out of the box, enabling users to fine-tune their model specification. In this regard, it is similar to the very popular scikit-learn package, but I have found the main difference between the two is that statsmodels is more for introspecting single models, while scikit-learn provides a powerful, object-oriented interface for creating predictive pipelines.
Happy Thanksgiving!
- 23 November 2022
Hi all, for the upcoming US holiday, I wanted to share some some turkey with all of you! Actually though, which I managed to make a turkey in everyone’s favorite drawing tool matplotlib.
While I would not recommend doing this, it was a fun way to learn more about some of the lower level interfaces that matplotlib offers. I hope you all enjoy the holiday if you are celebrating!
How Much Fun Was PyData NYC 2022?
- 16 November 2022
Hi everyone! It’s been a few weeks since I’ve written a blog post, but I have to share the events that were the highlight of last week: PyData NYC 2022.
I want to start off by thanking the amazing volunteers who put together the conference—from others on the organizing committee to the in-person volunteers who assisted with sprints, registration, talks, tutorials, and much more. Thank you for all of your time and help! It made for a true sense of community.
Hashability vs Mutability
- 06 October 2022
What is the actual difference between something that is hashable and something that is mutable? Why does this distinction even exist in Python?
One of our favorite questions here at Don’t Use This Code is: “What is the difference
between a list and a tuple?” This often leads to some discussion of hashability
and mutability, but even more interestingly, we talk about the use cases of a list
vs a tuple. When do they come up in code? Why are they used for different purposes?
Why not always use a list?
The Central Limit Theorem - Visualized
- 28 September 2022
For this week, I’m finally sharing the code I wrote to produce my visualization demonstrating the Central Limit Theorem! But before we get to the code, I wanted to discuss the impact of this visualization and how it can be interpreted.
This is a very brief background & example of the Central Limit Theorem and is not intended to be comprehensive.
pandas Groupby: split-?-combine
- 21 September 2022
- English
When choosing what groupby operations to run, pandas offers many options. Namely, you can choose to use one of these three:
agg or aggregate
Unconventional Pandas: Colormaps
- 14 September 2022
- English
Hello everyone! We have some exciting events coming up, including a NEW seminar series and a code review workshop series. In our brand new seminar series, we will share with you some of the hardest problems we have had to solve in pandas and NumPy (and, in our bonus session on September 16th, hard problems that we have had to solve in Matplotlib!). Then, next month starting October 12th, we will be holding our first ever “No Tears Code Review,” where we’ll take attendees througha a code review that will actually help them gain insight into their code and cause meaningful improvements to their approach.
Let’s get to the exciting content!
President Rankings - a pandas challenge
- 08 September 2022
- English
Welcome back to another edition of Cameron’s Corner! We have some exciting events coming up, including a NEW seminar series and a code review workshop series. In our brand new seminar series, we will share with you some of the hardest problems we have had to solve in pandas and NumPy (and, in our bonus session, hard problems that we have had to solve in Matplotlib!). Then, next month starting October 12th, we will be holding our first ever “No Tears Code Review,” where we’ll take attendees througha a code review that will actually help them gain insight into their code and cause meaningful improvements to their approach.
I recently received a question about webscraping and pandas and wanted to share with you an example I had come across. As with most code I run into online, I thought to myself, “What I would change if I wrote this from scratch.”
Estimating The Standard Deviation of a Population from a Sample
- 31 August 2022
- English
Welcome back to another edition of Cameron’s Corner! We have some exciting events coming up, including a NEW seminar series and a code review workshop series. In our brand new seminar series, we will share with you some of the hardest problems we have had to solve in pandas and NumPy (and, in our bonus session, hard problems that we have had to solve in Matplotlib!). Then, next month starting October 12th, we will be holding our first ever “No Tears Code Review,” where we’ll take attendees througha a code review that will actually help them gain insight into their code and cause meaningful improvements to their approach.
For Cameron’s Corner this week, I wanted to take some time to talk about another statistical visualization I’m working on that covers Bessel’s Correction. Ready for some advanced matplotlib with a sprinkle of statistics? Let’s dive in!
Matplotlib Legends: Artists & Handlers
- 17 August 2022
Hey all, got some matplotlib for you this week. I wanted to start touching on some more advanced ideas about it and decided to demonstrate a question I answered on Stack Overflow not long ago.
The question asked about custom legend artists- essentially asking “How can I change the style of the artists matplotlib presents in a given legend.” While the longest way to do this is to construct a Legend manually, thankfully matplotlib provides an escape hatch in the form of the handler_map argument.
Working with Long Labels In Bokeh
- 10 August 2022
Hey all, I wanted to revisit a topic I discussed a few weeks ago and demonstrate how use deal with long labels in another one of my favorite plotting libraries in Python: bokeh.
In a previous post, I mentioned that I came across a fun blog post by Andrew Heiss covering how to work with long tick labels in R’s ggplot2. As I mentioned in my last post: “I couldn’t resist the urge to recreate the visualizations in and wanted to share with you how you can deal with long tick labels in Python!”
Quordle: Strategies
- 03 August 2022
- English
Following up from last week where I worked on adapting the Wordle game engine to also play Quordle. I wanted to take some time to see if we can play Quordle smarter. To do this, I wanted to design a few “cross-board strategies” to play Quordle with. When playing 4 simultaneous Wordle boards where each guess you make is applied to all boards, there is an important decision to make: which board to I focus my attention on for any given turn? Do I attempt to solve one board entirely before attempting to guess another? Do I sequentially rotate amongst these boards each turn? These are examples of what I mean by a “cross board strategy”
To get started, let’s port over all of the Quordle Engine code from last weeks post, and check to see that it still works.
Quordle: Engine
- 27 July 2022
- English
This week I wanted to revisit a fun project. Specifically, I wanted to try extending the code I wrote to play Wordle to see if I can get it to also play Quordle. For those of who are unfamiliar, Quordle is a similar word game to Wordle in that you guess 1 word per round to try and solve a puzzle. After each round you are provided with feedback per each letter with whether or not the letter appears in the word, appears in the word and is in the correct position, or does not appear in each word. Quordle takes this idea and adds another challenge: you must play 4 simultaneous games of Wordle.
When playing simultaneous games, you must use the same guess across all Wordle boards. For each round, you are provided with the same feedback and if you guess correctly you are finished with that specific board. This extension opens up for new and interesting strategies (which boards do I solve first, how do I go about picking good candidate words) as well as interesting models & maintenance of game state and display.
Working with Long Labels In Matplotlib
- 20 July 2022
Hey all, I came across a fun blog post covering how to work with long tick labels in R’s ggplot2. I couldn’t resist the urge to recreate the visualizations in matplotlib and wanted to share with you how you can deal with long tick labels in Python!
First we’ll need some data- using the same source as the above linked blog post, we can fetch and process our data like so:
Simplifying Logic In Your Python Code
- 13 July 2022
Last week I took a deeper look into some ideas covering boolean logic and how we can derive expressions from truth tables. In that same spirit, I wanted to share my absolute favorite example from my seminar on logic where I covered expression simplification and how it can be used to simplify valid Python flow control statement expressions. Additionally, this approach enabled us to determine whether specific branches were unsolvable meaning that there are branches of code that can never be executed due to a poorly formed conditional statement.
Since we covered how to use The simplify_logic function from SymPy to simplify boolean expressions last week, I wanted to dive straight into parsing Python code using the built-in Abstract Syntax Trees (ast) module. This module exists to parse Python code according to its own grammar rules in a programmatic manner. We can essentially represent valid Python code as a graph of nodes, accounting for various expressions and statements while also inspecting those aspects a little further- and even injecting some custom processing behavior.
Karnaugh Maps In Pandas
- 06 July 2022
As many of you know, I held a session on Logic this past month as part of “All the Computer Science You Never Took in College”. While I have never taken a computer science class in my life, I resonated with many of these concepts as things that I had encountered
A fun example that I presented used pandas to simplify a boolean algebra expression via a Karnaugh map. Karnaugh maps are useful tabular representations of boolean expressions that we can use to visually simplify this expression to a disjunctive form.
Pandas: SettingWithCopyWarning
- 29 June 2022
- English
Wrapping up June already?! I can’t believe how quickly things are moving.
I wanted to take some time today to discuss one of the most common issues facing pandas users: SettingWithCopyWarning
Combinatorics in Matplotlib
- 22 June 2022
- English
Happy Wednesday everybody! This past week, I held a seminar on Logic as part of our series on “The Computer Science You Never Took in College”. We covered many topics around logic- including binary logic and operations, set operations, propositional logic, and combinatorics!
Today I would like to discuss the latter topic while also breaking down a fun
matplotlib-based example I used to highlight the different combinatoric
functions we have available to us in Pythons standard library itertools.
2022-06-15 PyData London - James Powell Review
- 15 June 2022
Can you believe James presented at PyData London every year from 2015-2019? This year, he is returning to the live stage to deliver another exciting talk on pandas and API design. So, if you’re attending the conference, this is a talk you won’t want to miss!
With the conference rapidly approaching (June 17-19), I wanted to take some time and review all of the past talks James has given at PyData London. I provided some commentary on the talks themselves as well as provided a rating out of 5 stars. As per usual, James’ talks are extremely insightful and bring a fresh perspective to familiar topics. I hope you all enjoy these as much as I did.
NumPy - Views vs Copies
- 08 June 2022
- English
Hey everyone! I can’t believe we’re half way through the year already. We have been extremely busy working on seminars for the rest of the year, as well as putting together some special events for our VIPs and alumni network.
We held VIP session at the end of last month wherein we challenged James to live-code the game of UNO from scratch. While UNO ended up being a much more complex game than any of us originally anticipated, James was able to accurately recreate the game, and he shared many helpful tips-and-tricks along the way.
Wordle From Scratch
- 01 June 2022
- English
This past week I led a live-coding seminar where I built and reviewed the popular word game Wordle from scratch. This was a fun live-coding project where I iterated on a few key components of the game. To start things off, we drafted all of the components needed to recreate Wordle:
An unknown word
Decorators: Reinventing the Wheel
- 28 May 2022
- English
Hey everyone, welcome to another week of Camerons Corner! This is going to be my last post on decorators for a little while, so I wanted to take some time and expand on what packages you might see decorators in and how I would implement them if I had to from scratch. In this post, I’m going to reinvent the wheel- that is you’ll see code I’ve written to replicate popular decorators from many third party packages. I am aiming to replicate only the core functionality of these decorator patterns in order to better highlight that these mechanisms are not something magical. There is real code underlying these patterns that enable unique design patterns.
When writing these examples, I only looked at various documentation pages & examples that use these decorators. No source code was examined or copied.
Python: Advanced Decorators
- 21 May 2022
- English
In a previous post, I shared a primer on how to approach the thinking of decorators and when we can apply them in our code. To summarize, we primarily see 3 entry points where decorators can dynamically effect our code:
entry point
Matplotlib: Place Things Where You Want
- 18 May 2022
I have recently done a couple of seminars on matplotlib. Among these seminars I demonstrate how to conceptually approach matplotlib: its 2 apis, convenience layers vs essential layers, dichotomous artist types, and coordinate systems/transforms.
Once you understand these ideas, the entire utility of matplotlib begins to snap into place. This week, I want to highlight one of these concepts: coordinate systems & transforms. The first step to making an aesthetically appealing graphic is to have confidence in placing Artists where you want them. Their existance (or lack thereof) on your Figure should not be a surprise, and by understanding matplotlibs coordinate systems we gain more power over the aesthetic of our plots.
Python: Decorator Fundamentals
- 14 May 2022
- English
Python has had the standard @decorator style decorator syntax since PEP 318 – Decorators for Functions and Methods was accepted, while some tweaks to the grammar have been made a long the way via PEP 3129 – Class Decorators and PEP 614 – Relaxing Grammar Restrictions On Decorators, their behavior has remained largely unchanged.
The most common misconception about decorators is that they are a function that takes a function and returns a function. While this does describe a common pattern for decorators, it ignores their generalized framework and misses strong usecases for decorators. Instead, I will say that a decorator is a callable that takes a class or function as an argument to encapsulate/manipulate some state and/or prepend/append some behavior to that class or function. While that definition is quite verbose, I think the following code snippets will help make my point.
Structured Objects: namedtuple
- 04 May 2022
- English
In one of our recent classes, the topic of structured objects came up. While discussing the tuple as an object that is typically used to model entities or tie together features of a single entity. In our discussion we compared the built-in tuple and namedtuple to assess the uses of either and see how we can improve the intent of our code using the namedtuple to model single entities.
Before we go too deep into the
Pandas - What Else Can You .groupby?
- 02 March 2022
- English
Hey there! Welcome to the first DUTC newsletter of March 2022! We have had an action packed start to the year and are eager to keep the trainings coming. Next month, in March, we are unveiling a new lineup of weekly seminars titled: Confident Queries & Stronger SQL. Where we will help to not only refine your SQL skills, but also but also convey the underlying framework and mental models that power the most commonly used database querying language in the world. And if that isn’t enough to get excited about, then you should be excited for my next presentation where I’ll be comparing Pandas vs SQL to address the similarities and differences between these tools. What types of analyses are possible with either tool, how often do they overlap, and when they do- which one should I use? All of these questions and more will be answered this March! So make sure you register now for our SQL seminar series.
Not only do we have SQL sessions upcoming, but we also have an upcoming Developing Expertise in Python and pandas course this April 18-21! Our developing expertise courses are easily my favorite content we offer. The ability to sit down in a small group and address problems in a paired-programming environment provides the most impactful form of learning. Not only do you get to ask any question about syntax, concepts, and approaches- but you can do so in a safe environment while learning best practices within the PyData stack. If you want to bridge the gap from an intermediate Python programmer to become an expert Pythonista (RUN THIS TERMINOLOGY BY JAMES), then I can not recommend this course enough. We work tirelessly to create a balanced and custom curriculum to meet the goals of all of our attendees.
Exceptions - Following a traceback
- 01 January 2022
This workshop will help you understand how to read and understand error messages in python.
Understand what Exceptions are and differentiate from the traceback